Building an Open Source tech platform for agriculture
In a previous blog, we explained how data is fuelling Odisha’s agricultural transformation through the Decision Support System (DSS). To recap, DSS is the powerhouse pulling agriculture data from 20+ different databases (like predicted rainfall data from the Indian Meteorological Department system, Mission for Integrated Development of Horticulture scheme data from the Central government system and the Jalanidhi scheme data from the NIC Odisha system). This is in addition to the data that is being captured on the platform itself (like data of 50+ agriculture schemes, Pradhan Mantri Fasal Bima Yojana claims disbursement data and crop coverage data of multiple crops). In essence, DSS houses all relevant data points related to agriculture that can help a government official at multiple levels make data-backed decisions. This blog delves into the tech principles on which DSS is built.

Written by
Kalpesh Agrawal
August 31, 2020
1) Using only Open Source components
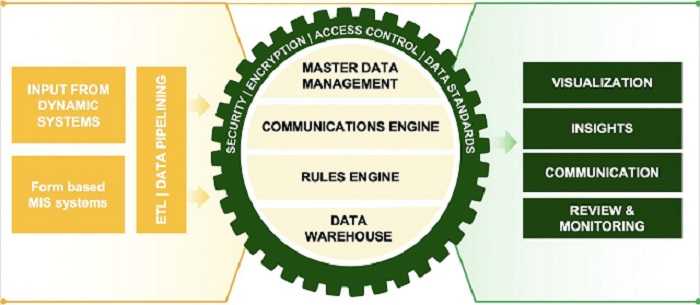
The tech stack used to build DSS is PHP Laravel with MySQL database. The diagram below explains the different components of the system.
Typically, data feeding will happen in either of three ways:
- Data collection forms: We are leveraging Open Data Kit (ODK), a Open Source tool, to collect unstructured data on DSS and its mobile app version (Agri Extension app). In addition, we have built a configurable forms module on DSS that allows the government officers to configure forms for collecting data of any existing/new scheme launched in the state.
- Application Program Interface (API)/Web-service or Database: We are using the Community version of Talend Open Studio to extract, transform/perform calculations and feed data in the DSS from other agriculture-related tech systems in the state.
- File uploads: We are creating jobs, which are essentially a combination of drag and drop components provided in the Graphical User Interface (GUI) of Talend Open Studio to extract data from a file, transform/perform calculations on the data and store the data in the database.
The following diagram provides an overview of the architecture of working of file uploads on DSS:
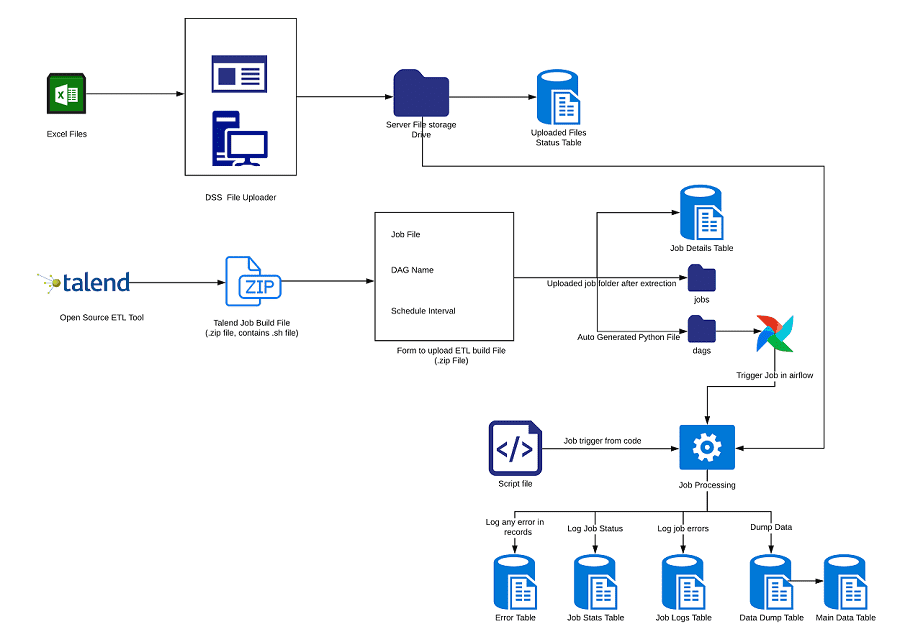
- Data pipeline: For scheduling jobs and data extraction configurations created in Talend, we are using Apache Airflow, which is an Open Source workflow management platform.
- Data visualisation: To visualise all the data captured from different sources and to create insightful dashboards, we are leveraging Superset embedded dashboards on the DSS. Superset is an Open Source tool that can be used to create a chart/dashboard based on data points captured in the database.
2) Configurable by the user
DSS has been designed in a manner that future use cases can be enabled with minimal dependence on engineers.
Data collection is configured by ODK tool, the configurable forms module and the Talend jobs. The dashboards from the data collected is powered by Superset where any chart/dashboard can be configured by the government officer without dependency on the engineers
In addition, we have created a configurable Schemes module on DSS which allows government officers to configure forms to collect scheme targets and achievements against these targets . Currently, the module has been used to digitize 56 agriculture schemes in Odisha and will be leveraged to digitize any new scheme launched by the state government in the future.
Furthermore, DSS is powered by a configurable access control module which enables the user (admin) to create login credentials for any officer and limit access/visualizations for that officer
3) Scalable
We have built DSS on a scalable architecture.
Currently data being collected on DSS is collected at various administrative levels like district, block and gram panchayat, depending on the availability of data. But the database schema of DSS is designed to accept data at any administrative unit from state to village. So if data being collected today is at the district-level and next year the data is collected at the block level, the database schema will not require any changes.
The peak traffic on the DSS servers is around 300 API calls/sec but we have optimized the servers to handle approximately 1,000 API calls/second.
Currently, the data volume being handled by DSS is nearly 20 lakh farmers across various agriculture dimensions during just one agriculture season (Kharif) of the year. To manage the volume of data flowing into DSS at all times, we have implemented table partitioning, which is essentially storing data in partitioned tables as opposed to storing it in one table. The partitioning of tables can be done based on any logic (say for example season or year)
4) Offline support
In many parts of Odisha, internet connectivity is absent or weak. Therefore, the AgriExtension app has been designed to handle use cases in offline mode with syncing functionality when the internet is available.
The principles on which DSS was built have helped the state government:
- Develop an agriculture tech platform which is self-sustaining with minimal dependency on engineers for rework.
- Avoid the use of any purchased software/tools/solutions and leverage Open Source tools and components which eliminate licensing fees or annual maintenance costs charged by software providers.
- Develop a platform which can be replicated by any other state or another country with a similar context.
Explore More Blogs


Simran Bagga and Amit Gupta
|March 7, 2025
Kumbh Sah'AI'yak: Bringing AI to the Common (Wo)man at the World’s Largest Congregation
Large Language Models (LLMs) have gained significant traction, transforming how information is accessed and processed across industries. Governments worldwide are actively exploring AI’s potential, and in India, initiatives like the IndiaAI Mission highlight this shift. In this evolving landscape, Samagra pioneered Kumbh Sah'AI'yak—an AI chatbot designed to assist pilgrims at the Prayagraj Mahakumbh. This blog delves into Samagra’s approach to leveraging AI for large-scale citizen impact, showcasing how AI can be built, customized, and deployed to address India’s unique governance and service delivery challenges.
Read more
Gautam Rajeev and Vijeeth Srinivas
|March 31, 2023
Leveraging Artificial Intelligence to deliver advisory to farmers
Which variety of paddy seeds should be sown for the upcoming Kharif season to generate maximum yield in accordance with changing agro-climatic conditions? What schemes can one avail to reduce the expenditure incurred in purchasing cattle feed? These are some of the many intricate decisions that farmers take through a given season- decisions that are determinants of yield, output realisation, and income.
Read more
Gautam Rajeev and Siddhant Agarwal
|January 16, 2023
Leveraging Data Science algorithms to improve data quality in government
One of the biggest joys while solving a data science problem is the realization that the data needed to solve the said problem is actually available. This joy is even more profound when solving a problem related to government data. The flip side, however, is that data collection in the government ecosystem is often like a game of Chinese Whispers.
Read more